Guida Pratica alla Creazione di una Pipeline RAG con n8n: Un Approccio Dettagliato
La creazione di una pipeline RAG (Retrieval-Augmented Generation) spesso parte da un obiettivo semplice, ma può rapidamente rivelarsi più complessa del previsto. Quella che sembra una funzionalità minore può trasformarsi in un insieme di servizi, script e file di configurazione, dove anche piccole modifiche possono innescare frequenti malfunzionamenti. Ciò che dovrebbe essere un modo agevole per ancorare un modello ai propri dati si ritrova sommerso da codice "colla" e complessità di deployment, rendendo l'implementazione dell'idea centrale più ardua. È in questo contesto che n8n, con le sue funzionalità RAG, si distingue. La piattaforma consente di costruire l'intera pipeline RAG all'interno di un unico workflow visivo, selezionando i modelli e i database vettoriali desiderati ed eliminando completamente la necessità di codice aggiuntivo. Il risultato è un metodo più semplice e affidabile per fornire all'intelligenza artificiale dati specifici e contestualizzati. Interessante, vero? Analizziamo più da vicino come funziona!
Perché la RAG è diventata Necessaria?
Prima di addentrarci nella pipeline di Generazione Aumentata dal Recupero (RAG), è utile porsi una domanda fondamentale: quali sono i limiti dei modelli di fondazione utilizzati in autonomia? La maggior parte dei team riscontra problematiche ricorrenti: i modelli tendono a generare informazioni inesistenti o non corrispondenti alla realtà (allucinazioni); non possiedono conoscenza dei dati interni specifici dell'organizzazione; e aggiornare la loro base di conoscenza senza dover riaddestrare l'intero modello risulta estremamente difficile.
Immaginate che la vostra azienda disponga di documentazione sui prodotti, ticket di supporto e guide interne. Se si pone a un modello di fondazione una domanda come “Il nostro piano enterprise supporta l’SSO con il provider X?”, il modello, non avendo informazioni specifiche sul vostro piano, tenterà di rispondere basandosi su schemi generali appresi da internet. A volte la risposta sarà vicina alla verità, altre volte sarà pericolosamente errata.
È evidente la necessità di fornire al modello un contesto aggiornato e affidabile al momento della query. Inoltre, è cruciale poterlo fare senza la necessità di riaddestrare il modello ogni volta che la documentazione subisce modifiche. Questo è il principio cardine su cui si fondano le pipeline RAG.
Cos’è una Pipeline RAG?
Una pipeline RAG (Retrieval-Augmented Generation) è un sistema progettato per aiutare un modello di intelligenza artificiale a rispondere a domande utilizzando i dati specifici della vostra organizzazione, superando i limiti delle conoscenze apprese durante la fase di addestramento.
Invece di pretendere che il modello "sappia tutto", una pipeline RAG gli permette di:
- Recuperare dinamicamente i frammenti di dati più pertinenti alla domanda posta.
- Arricchire il prompt con il contesto recuperato, consentendo al modello di formulare una risposta informata.
Si può immaginare questo processo come quello di un bibliotecario per il vostro modello linguistico. L'ingestione è l'atto di inserire i libri nella biblioteca. Il recupero è il processo di trovare le pagine giuste. L'aumento (augmentation) è il momento in cui quelle pagine vengono consegnate al modello. 💡 È interessante notare come in n8n ciascuna di queste fasi sia rappresentata da nodi all'interno di un unico workflow, evitando la frammentazione tipica di script distribuiti su più servizi.
Fasi Chiave di una Pipeline RAG
Le fasi principali di una pipeline RAG sono illustrate di seguito:
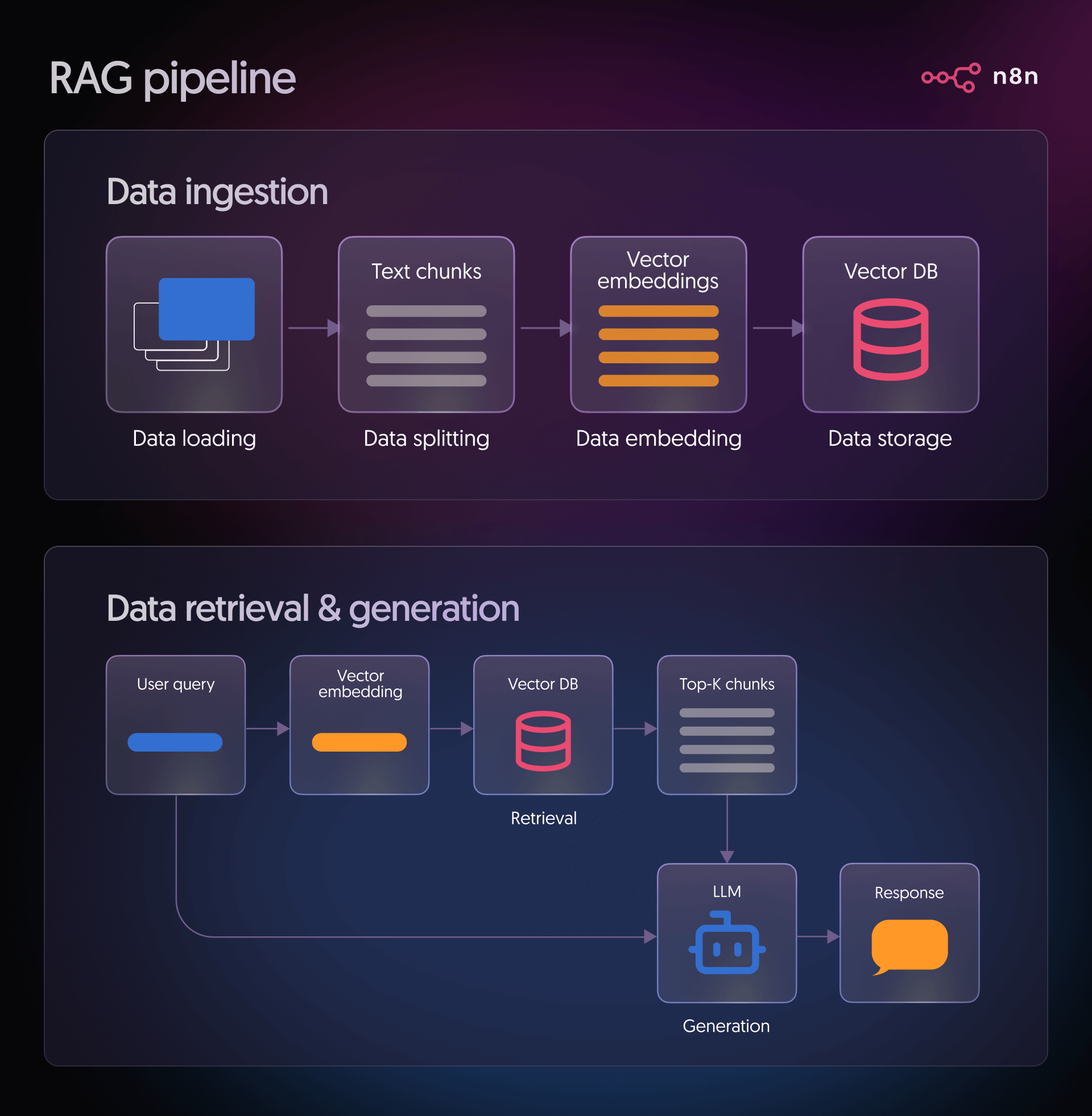
Fase 1: Ingestione dei Dati
Questa fase risponde alla domanda fondamentale: “A quali informazioni dovrebbe avere accesso il mio modello?” Le fonti tipiche includono documentazione di prodotto, articoli di knowledge base, pagine Notion, spazi Confluence, PDF archiviati nel cloud o ticket di supporto. Durante l'ingestione, il processo si articola in questi passaggi:
- Caricamento dei dati: In questa fase, ci si connette alla fonte prescelta per acquisire i documenti che il sistema utilizzerà. Si possono trattare di file, pagine o qualsiasi altro contenuto testuale su cui si basa la pipeline.
- Suddivisione dei dati: I documenti di grandi dimensioni vengono frammentati in segmenti più piccoli per facilitarne l'elaborazione da parte del modello. Questi frammenti sono generalmente mantenuti al di sotto di una dimensione specifica, ad esempio circa 500 caratteri, per ottimizzare la precisione del recupero.
- Embedding dei dati: Ogni frammento di testo viene trasformato in un vettore numerico utilizzando un modello di embedding. Questo processo converte il significato del testo in una forma numerica che il sistema può confrontare e elaborare.
- Archiviazione dei dati: I vettori così generati vengono poi inseriti in un database vettoriale. Questo consente agli utenti di individuare rapidamente i frammenti più pertinenti quando formulano una domanda.
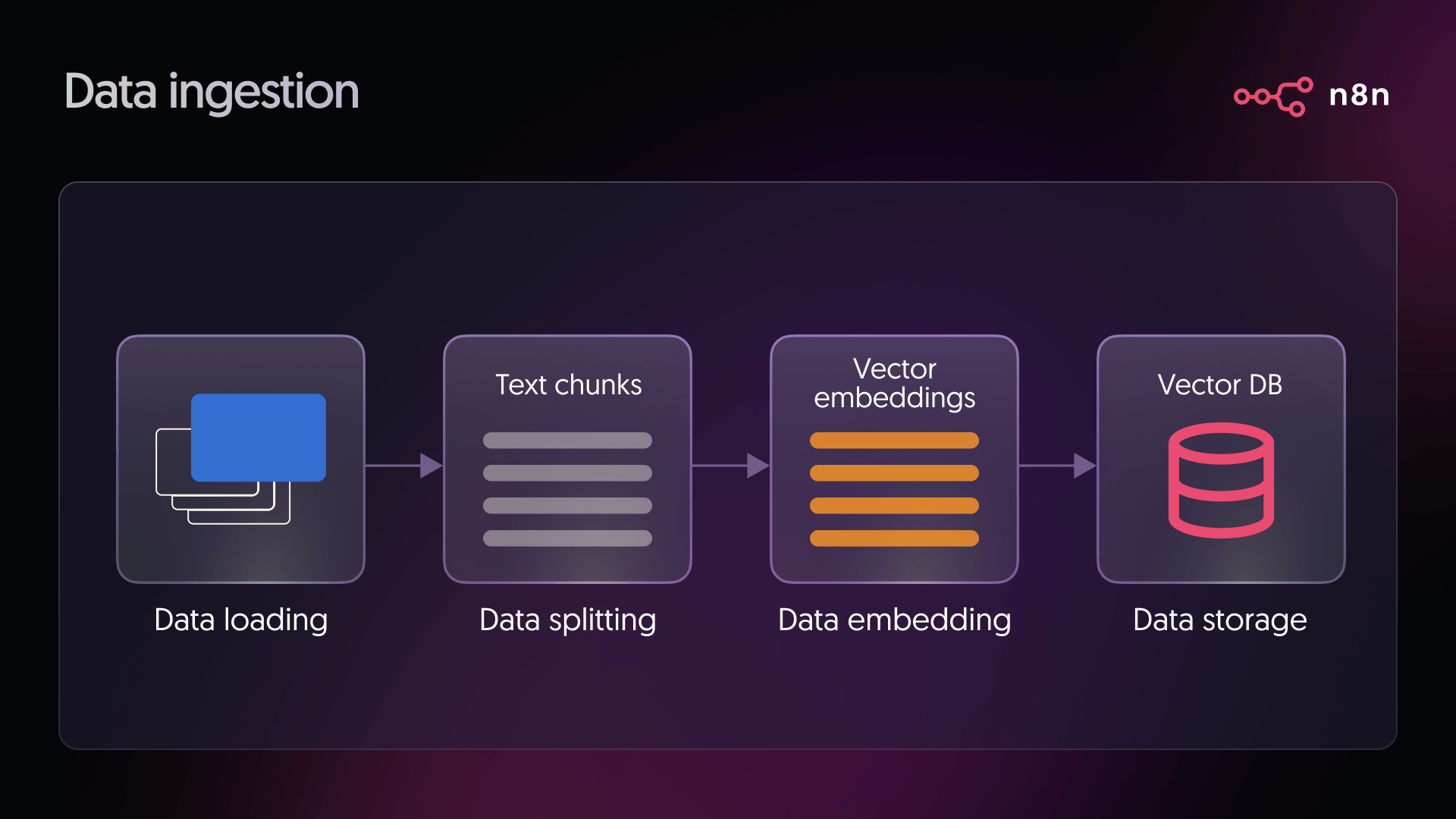
Nelle configurazioni tradizionali basate su codice, questa fase richiederebbe solitamente l'implementazione di diversi script e servizi. In n8n, molti di questi passaggi sono disponibili come nodi preconfigurati e pronti all'uso.
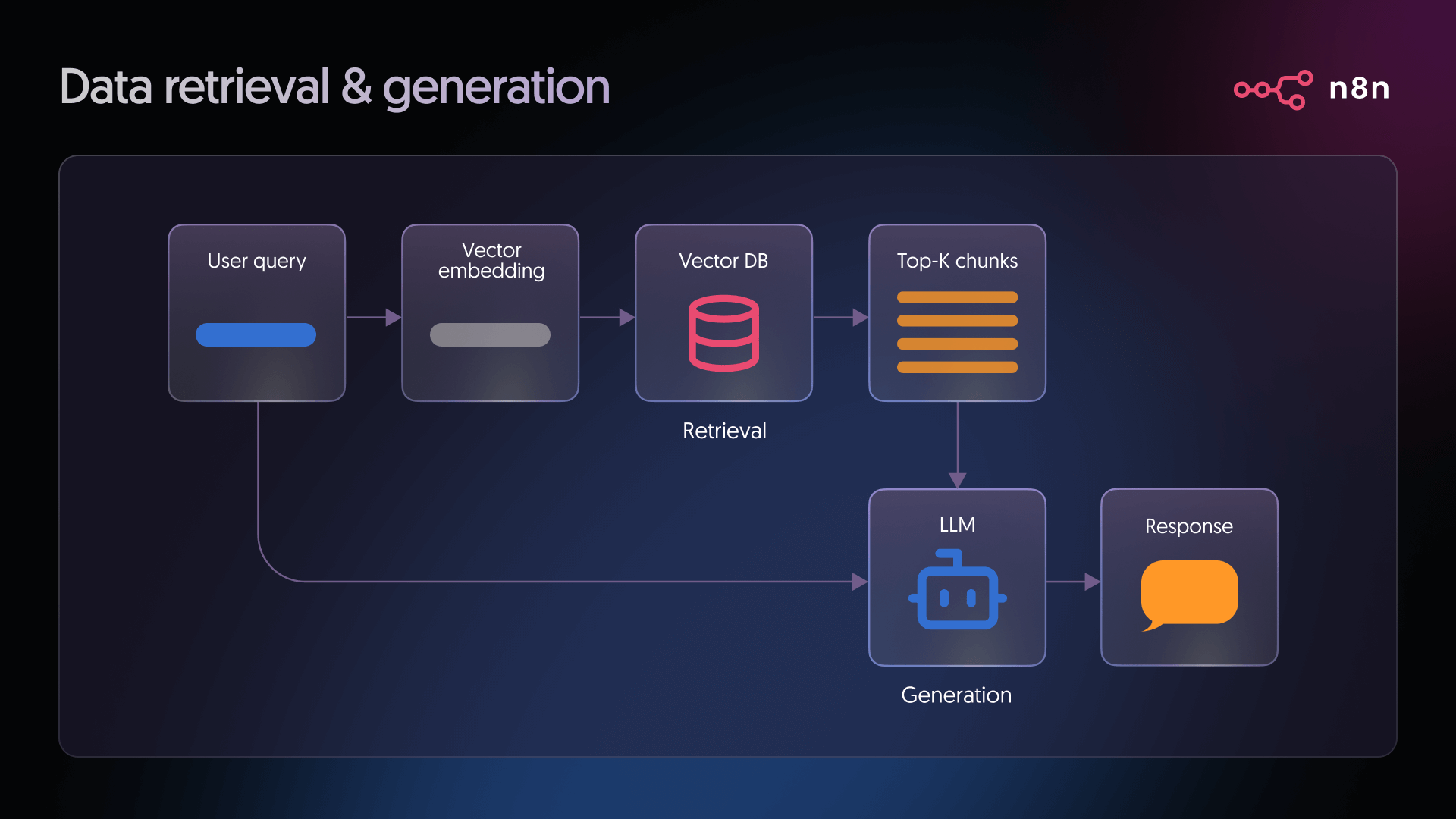
Fase 2: Recupero, Aumento e Generazione
Una volta che i dati sono stati ingeriti e indicizzati, la pipeline RAG procede con il recupero, l'aumento e la generazione della risposta:
- Recupero (Retrieval): Quando un utente pone una domanda, il sistema converte tale domanda in un vettore, impiegando lo stesso modello di embedding utilizzato durante l'ingestione. Questo vettore di query viene poi confrontato con tutti i vettori presenti nel database per identificare le corrispondenze più vicine. Tali corrispondenze rappresentano i frammenti di testo che con maggiore probabilità contengono informazioni utili per rispondere alla domanda.
- Generazione (Generation): Il modello linguistico riceve due elementi chiave: la domanda dell'utente e il testo pertinente recuperato dal database vettoriale. Integra entrambi gli input per produrre una risposta fondata e contestualizzata, utilizzando le informazioni recuperate come base per la propria elaborazione.
Come Costruire una Pipeline RAG in n8n
Per illustrare un approccio pratico e pronto per la produzione nella costruzione di workflow RAG, ci concentreremo sull'uso di n8n. Invece di dover gestire componenti isolati, n8n permette di progettare l'intera pipeline — dall'ingestione dei dati e la creazione degli embedding, fino al recupero, alla generazione e alle azioni post-risposta — in un unico ambiente centralizzato.
Prendiamo come esempio un workflow n8n che monitora nuovi documenti o aggiornamenti su Google Drive, li elabora automaticamente, ne archivia gli embedding in Pinecone e utilizza i modelli Gemini di Google per rispondere alle domande dei dipendenti basandosi su tali documenti. L'intero processo è contenuto in un unico workflow visivo, che richiede solo configurazione e nessun codice "boilerplate".
Ecco cosa avviene dietro le quinte:
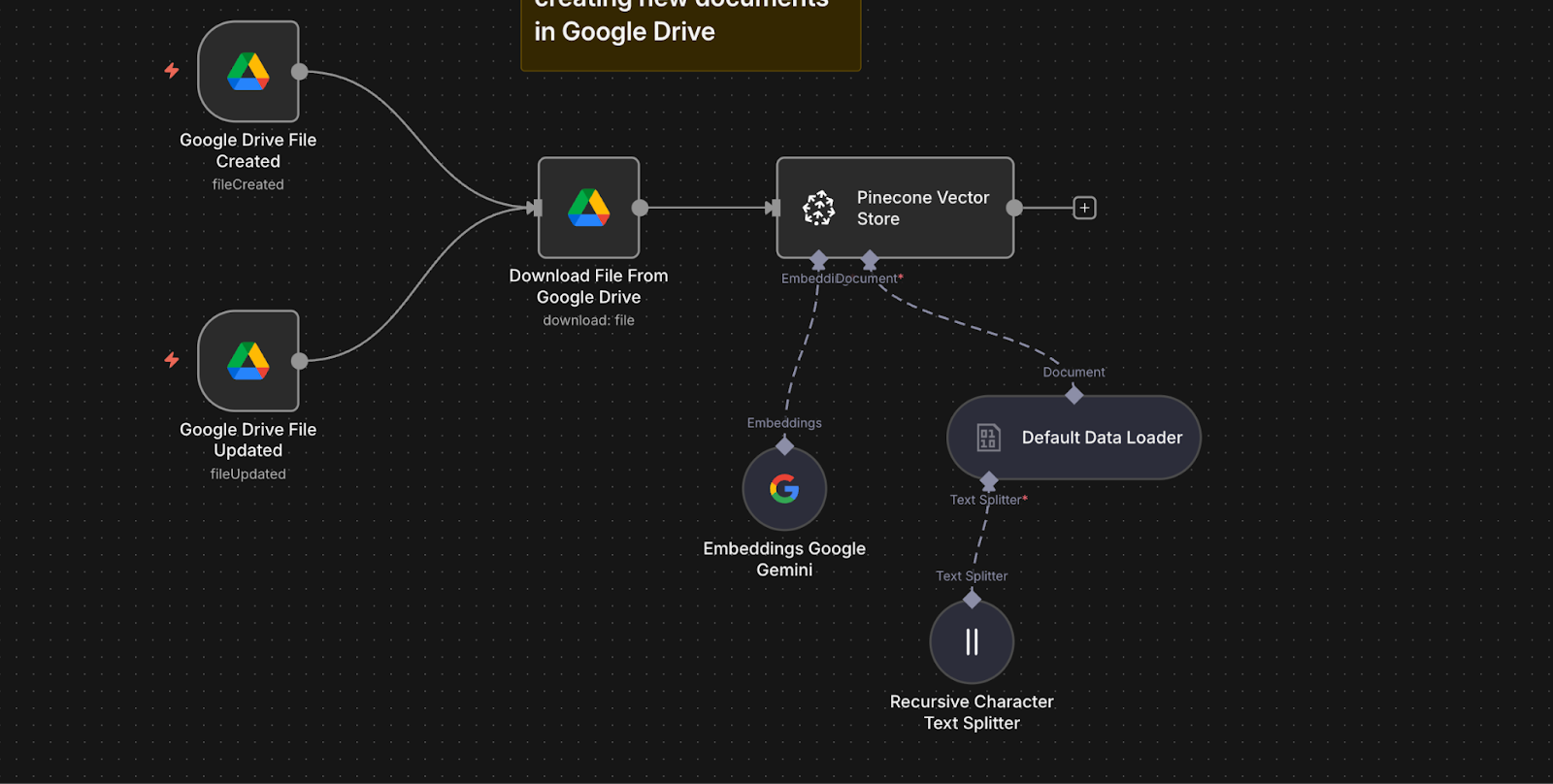
- Due nodi Google Drive Trigger monitorano una cartella: uno rileva i nuovi file, l'altro gli aggiornamenti.
- Quando viene rilevato un file, un nodo Google Drive lo scarica.
- Un nodo Default Data Loader estrae il testo dal documento.
- Un nodo Recursive Character Text Splitter suddivide il contenuto in frammenti più piccoli per ottimizzare il recupero.
- Un nodo Google Gemini Embeddings crea gli embedding per ogni frammento di testo utilizzando il modello
text-embedding-004. - Un nodo Pinecone Vector Store indicizza sia i frammenti che i loro embedding nell'indice Pinecone.
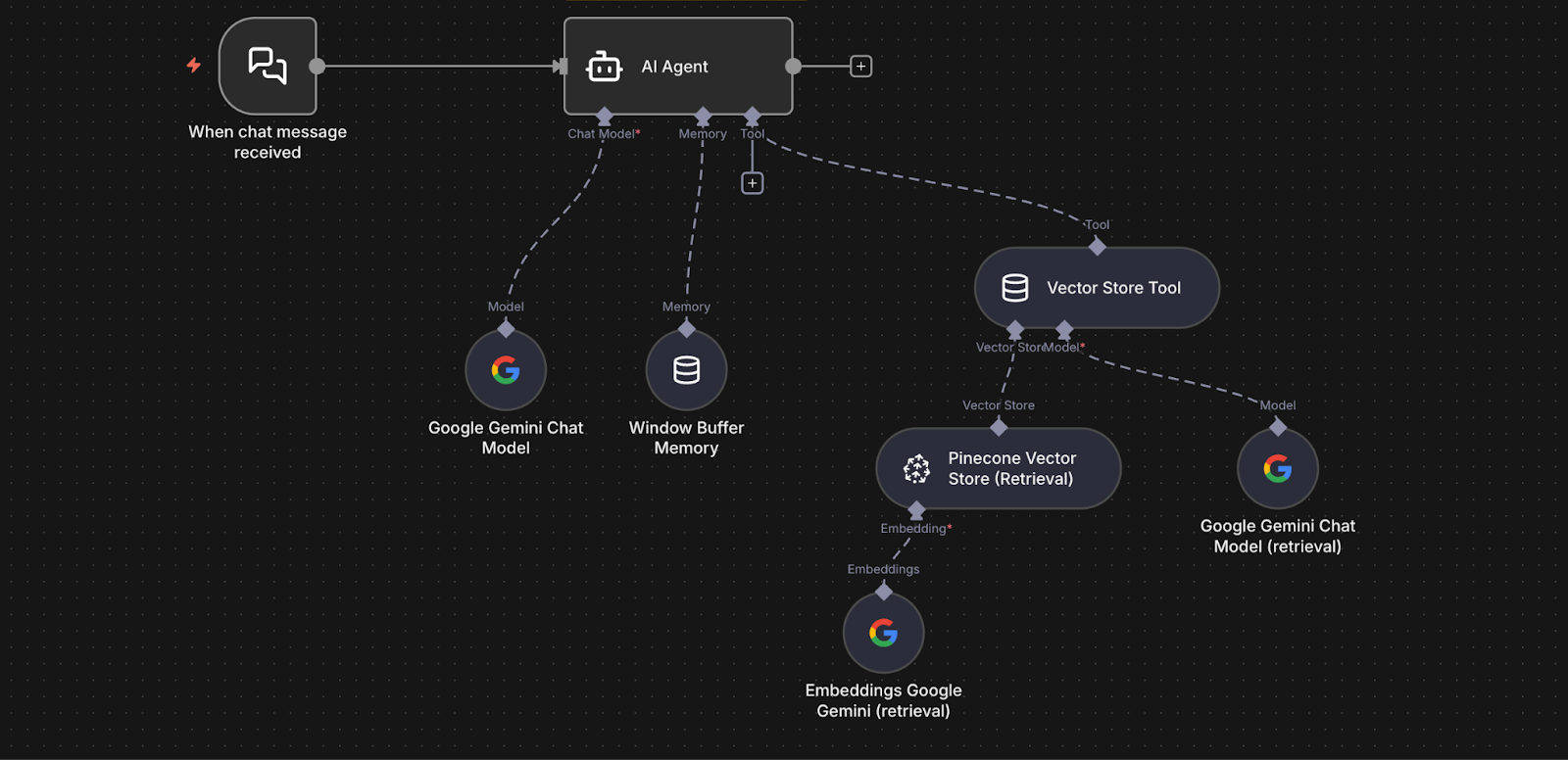
- Un nodo Chat Trigger riceve le domande dei dipendenti.
- La domanda viene passata a un nodo AI Agent.
- L'agente utilizza un nodo Vector Store Tool connesso a Pinecone in modalità query per recuperare i frammenti pertinenti.
- L'agente inoltra la domanda e i frammenti recuperati al nodo Google Gemini Chat Model.
- Gemini genera una risposta fondata, basandosi sul testo recuperato.
- Un nodo Window Buffer Memory consente una memoria conversazionale a breve termine, rendendo le domande di follow-up più naturali.
In sintesi, il workflow mantiene aggiornato l'indice dei documenti e lo utilizza per alimentare un chatbot intelligente e consapevole del contesto. Per eseguire questo workflow RAG nella propria istanza n8n, sono necessari alcuni passaggi di configurazione, ciascuno dei quali attiva una parte della pipeline descritta.
Hai Bisogno di Supporto Professionale?
Se desideri un aiuto concreto per configurare n8n, progettare workflow complessi, migliorare sicurezza e scalabilità o integrare l’automazione con i tuoi sistemi esistenti, puoi affidarti a un supporto professionale.
Il nostro team può accompagnarti dalla prima installazione fino a soluzioni avanzate su misura per il tuo business.
👉 Contattaci su https://cyberrebellion.site/it per una consulenza personalizzata.
Fase 1: Preparare gli Account
Per avviare la configurazione, sono necessari tre servizi specifici.
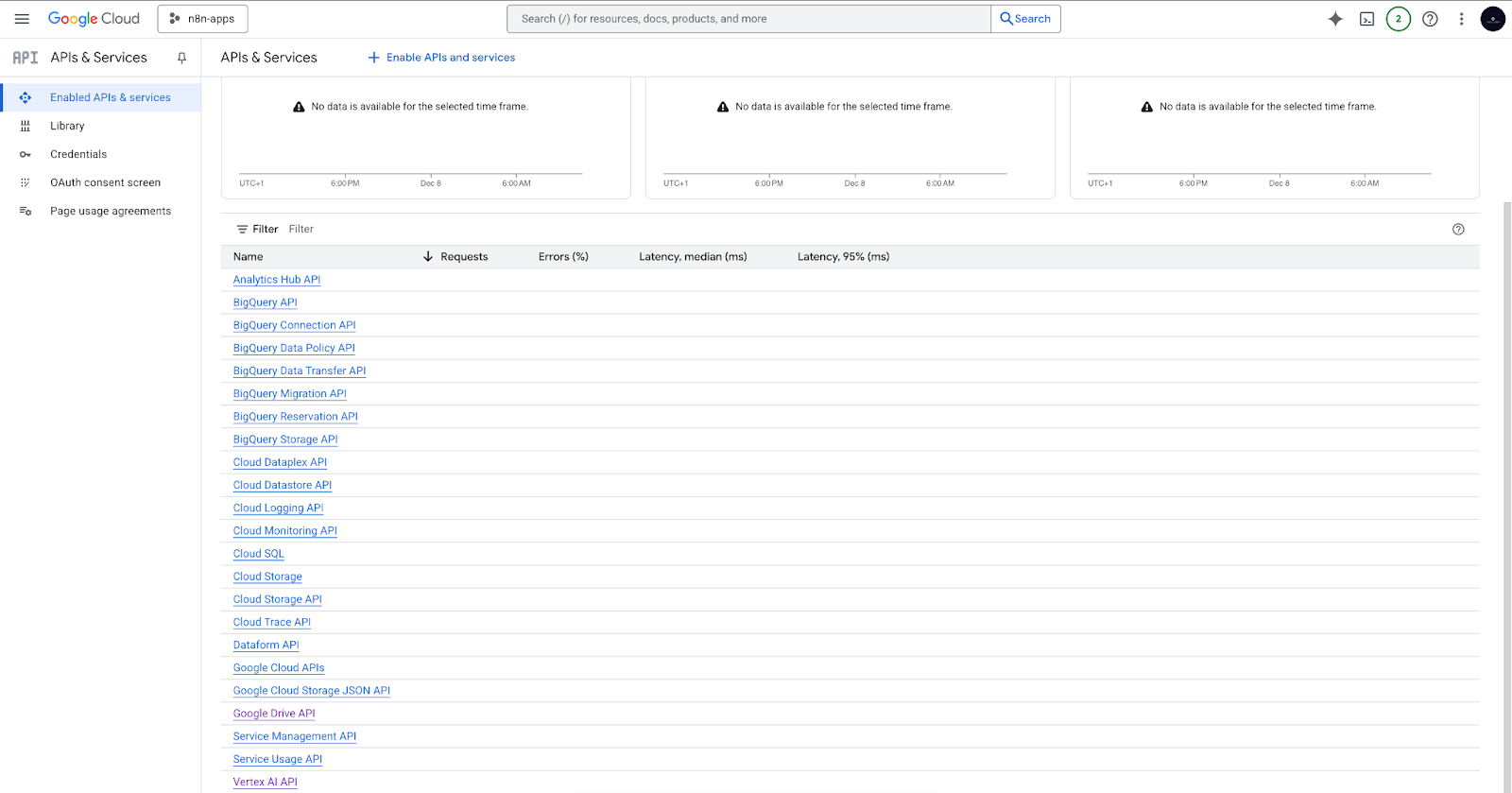
Progetto Google Cloud e API Vertex AI
- È necessario creare un progetto Google Cloud.
- All'interno del progetto, abilitare i servizi indispensabili: l'API Vertex AI (per i modelli di embedding e chat) e l'API Google Drive (per il caricamento e il monitoraggio dei documenti da Drive).
Dopo questi passaggi, le API Vertex AI e Google Drive dovrebbero essere visibili nell'elenco dei servizi abilitati.
Chiave API Google AI
- Ottenere la propria chiave API da Google AI Studio.
- Questa chiave sarà fondamentale per autenticare tutte le chiamate ai modelli Gemini da n8n.
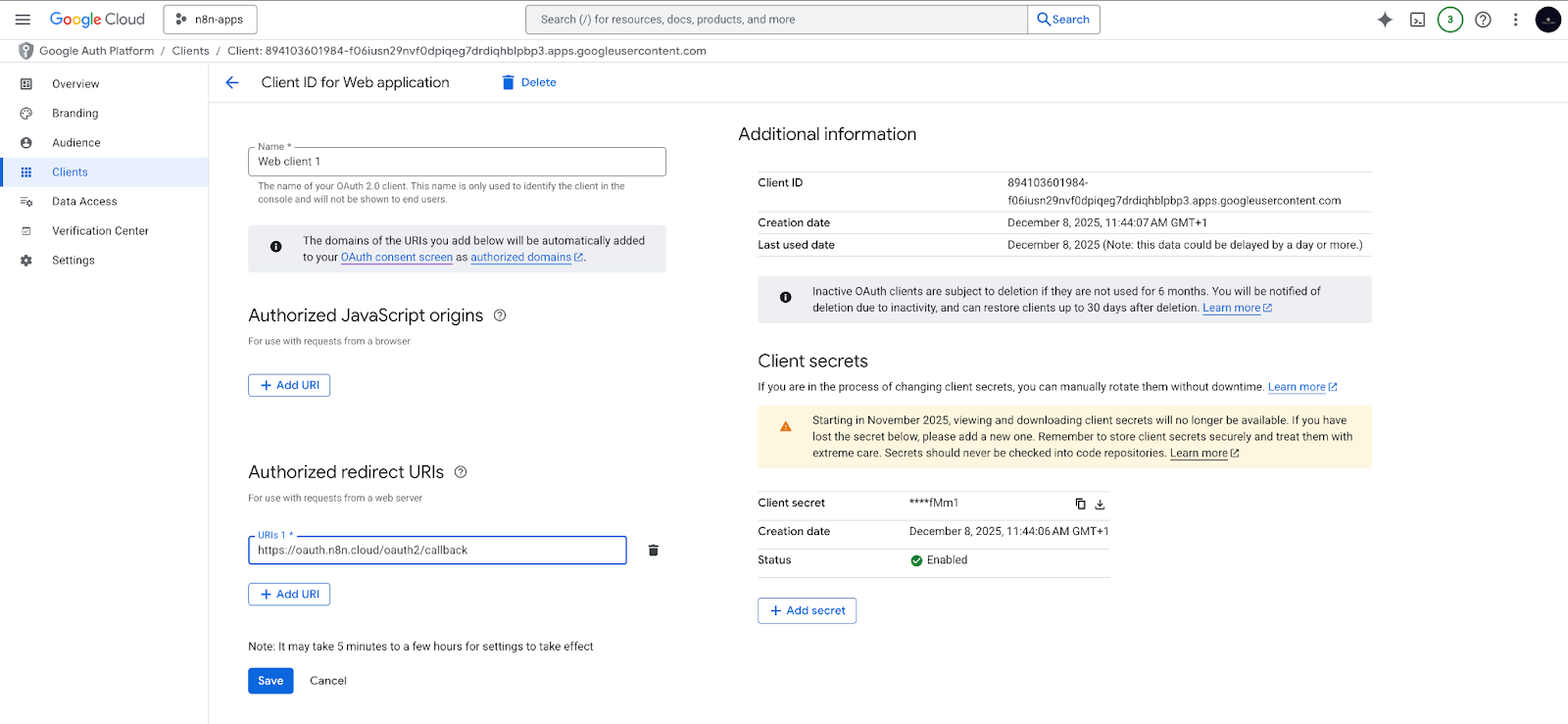
Credenziali Google Drive OAuth2
- Nel proprio progetto Google Cloud, creare un ID client OAuth2.
- Aggiungere l'URI di reindirizzamento corretto per l'istanza n8n.
- Utilizzare questa credenziale OAuth2 in n8n per autorizzare il workflow a leggere la cartella Google Drive specificata.
Account Pinecone
- Registrare un account Pinecone gratuito.
- Copiare la chiave API predefinita fornita.
- Creare un indice denominato
company-filesper archiviare gli embedding e i frammenti di testo.
Fase 2: Preparare la Cartella Google Drive
Creare una cartella dedicata in Google Drive. Questa cartella ospiterà tutti i documenti che il chatbot dovrà utilizzare come riferimenti. Il workflow monitorerà automaticamente questa cartella.
Fase 3: Aggiungere le Credenziali a n8n
Prima che il workflow possa essere eseguito, n8n richiede l'autorizzazione per comunicare con i servizi esterni. Questo si realizza creando le credenziali necessarie. In generale, per aggiungere qualsiasi credenziale in n8n:
- Aprire la propria istanza n8n.
- Fare clic su Create credential.
- Selezionare il servizio al quale si desidera connettersi. Ad esempio, è possibile selezionare il servizio Google Drive OAuth2.
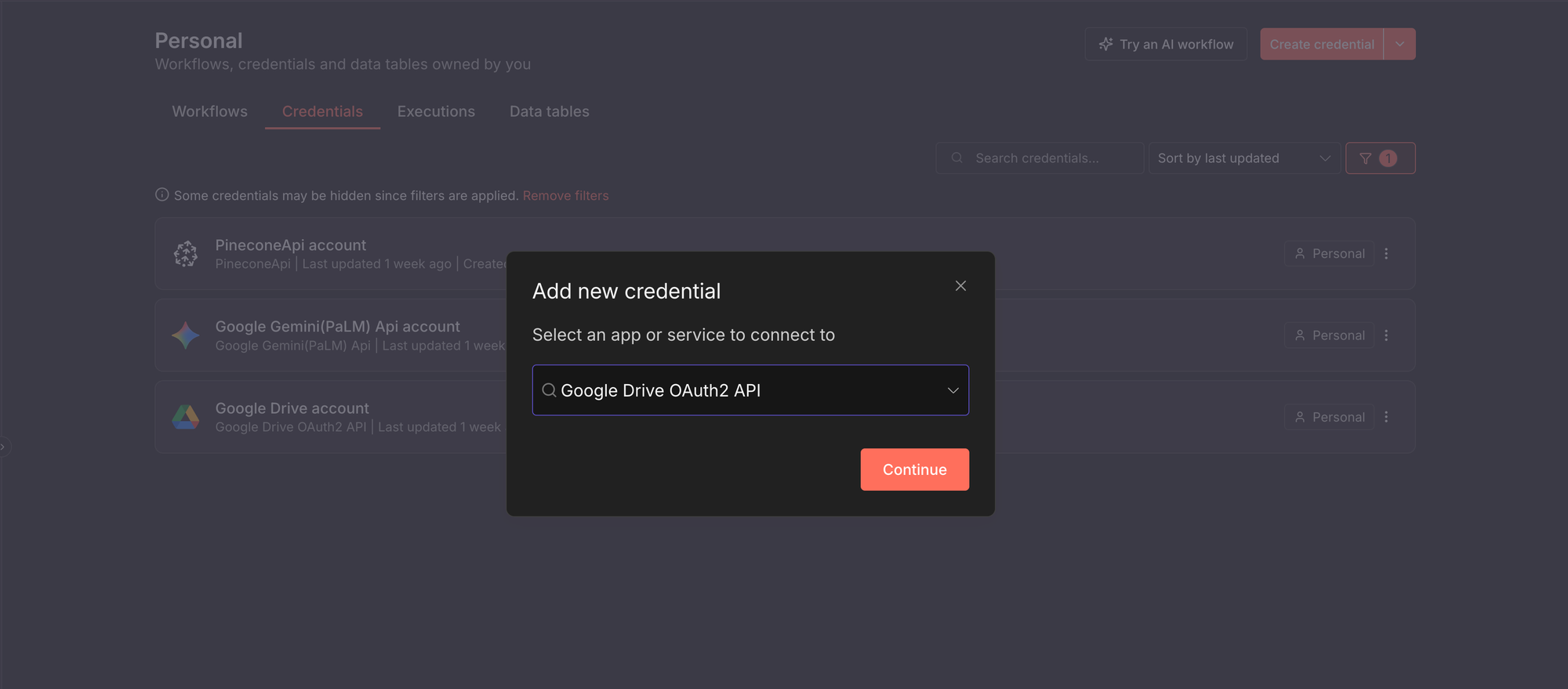
Per questa guida, è necessario configurare le credenziali per tre servizi:
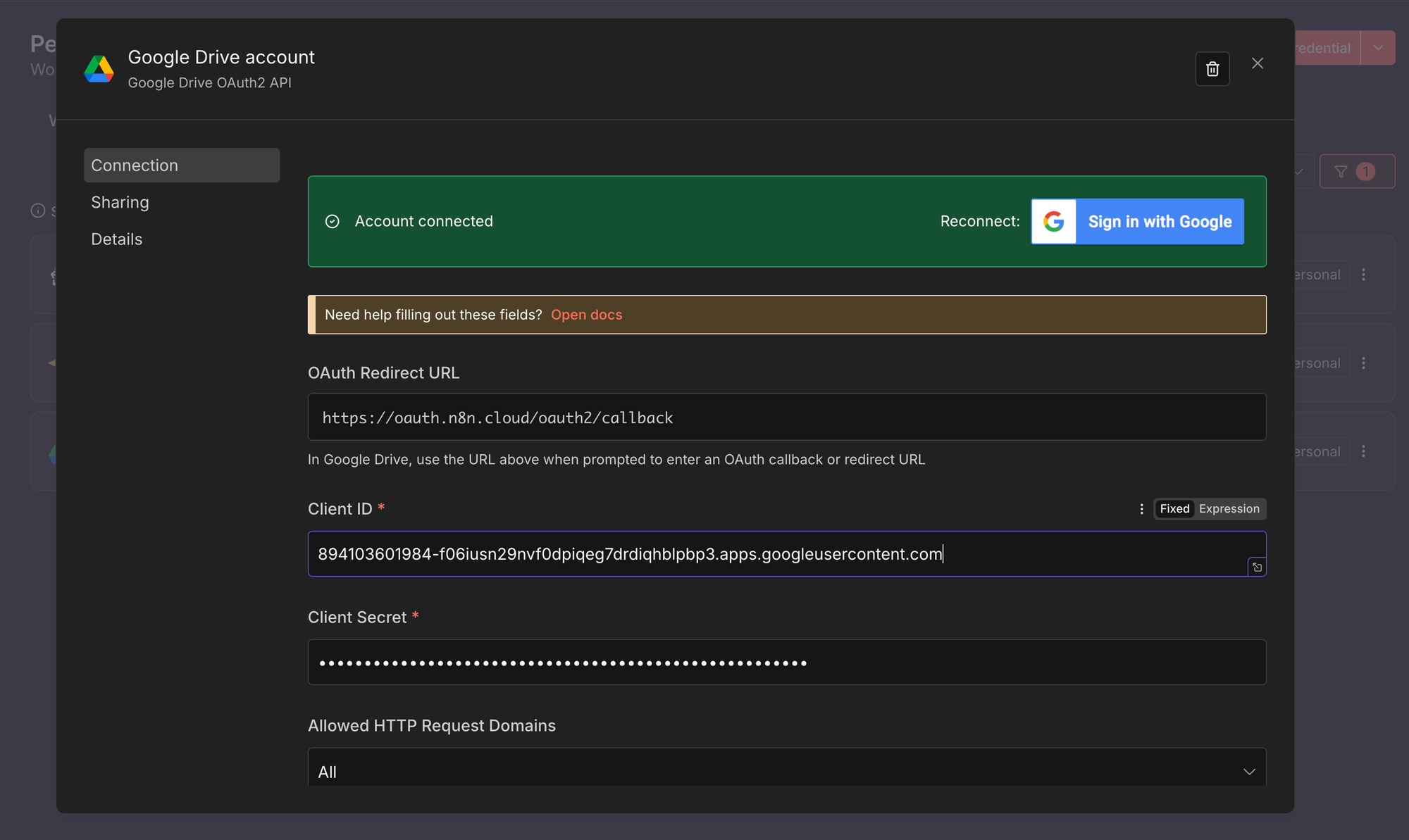
1. Google Drive OAuth2
Questa credenziale consente a n8n di leggere e monitorare i file nella vostra cartella Google Drive.
- Creare una nuova credenziale di tipo Google Drive OAuth2, seguendo i passaggi generali descritti.
- Inserire il Client ID e il Client Secret ottenuti dal proprio progetto Google Cloud.
- Fare clic su Connect e completare il flusso di autorizzazione di Google.
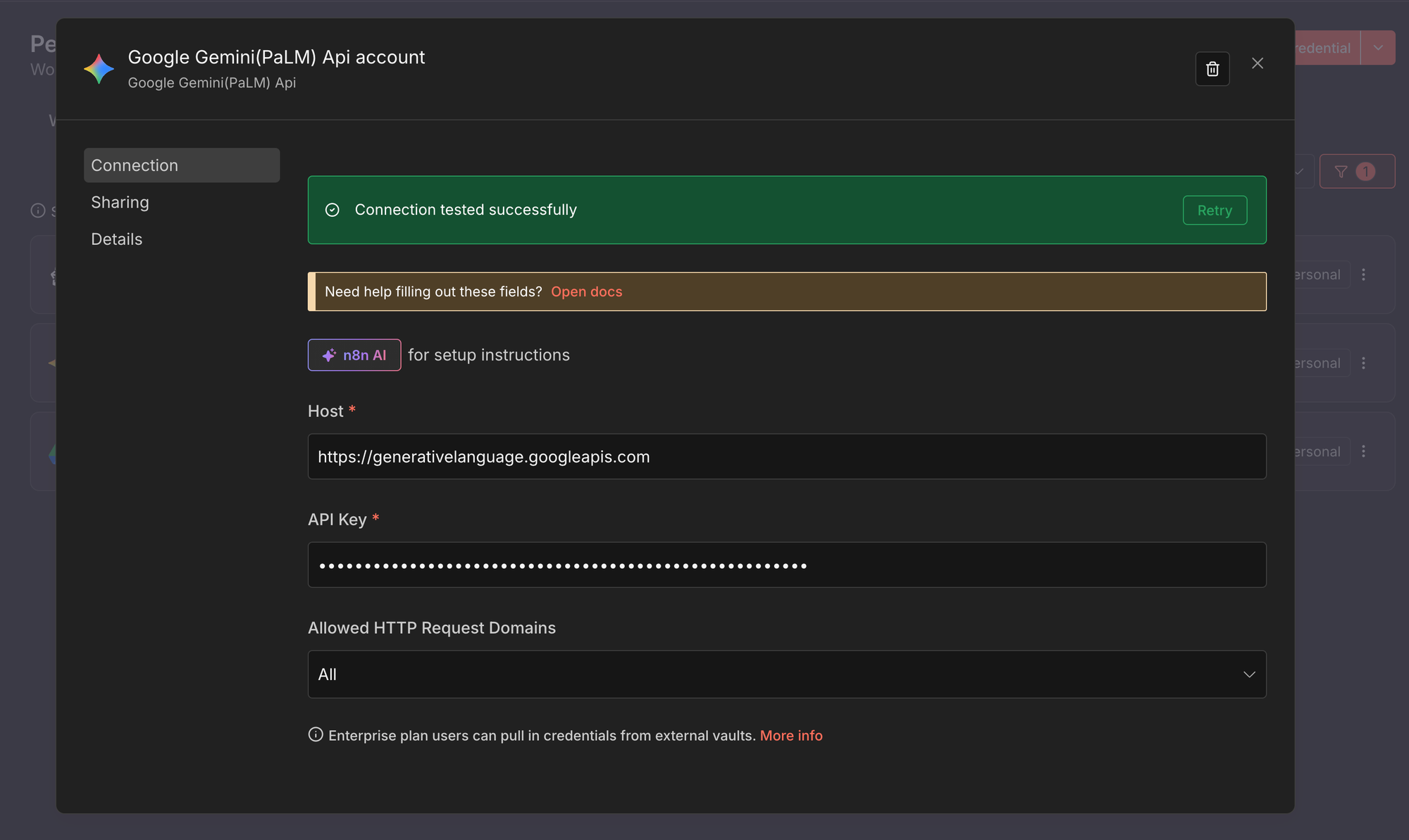
2. Google Gemini (PaLM) API
Questa credenziale è utilizzata per la creazione di embedding e la generazione di chat con i modelli Gemini.
- Creare una nuova credenziale di tipo Google Gemini (PaLM) API.
- Incollare la propria Google AI API key ottenuta da Google AI Studio.
- Salvare la credenziale.
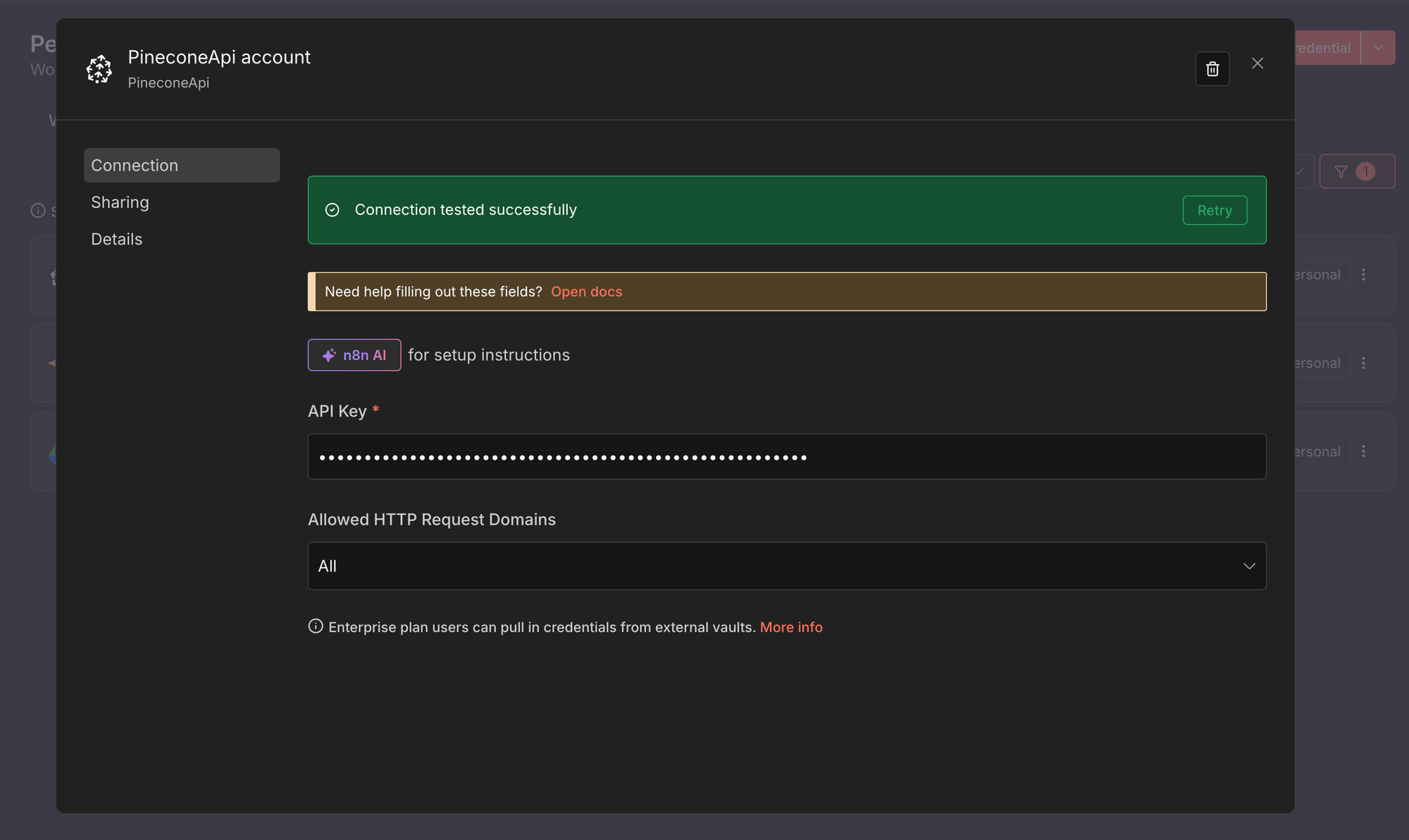
3. Pinecone API
Questa credenziale permette a n8n di archiviare e recuperare vettori dal proprio indice Pinecone.
- Creare una nuova credenziale di tipo Pinecone API.
- Incollare la propria Pinecone API key.
- Salvare la credenziale.
Una volta create, le credenziali potranno essere selezionate da qualsiasi nodo compatibile. Per una panoramica più approfondita, si consiglia di consultare la documentazione ufficiale di n8n sulle credenziali.
Fase 4: Importare il Workflow RAG
Scaricare o copiare il workflow e importarlo nella propria istanza n8n. Una volta importato, sarà possibile visualizzare l'intera pipeline RAG all'interno dell'editor, con tutti i nodi già collegati.
Fase 5: Configurare i Nodi
Personalizzare il workflow aggiornando alcuni nodi chiave:
- Aggiornare entrambi i nodi Google Drive Trigger affinché monitorino la cartella specifica creata in precedenza.
- Aprire i nodi Pinecone Vector Store e configurarli per puntare all'indice
company-files. - Verificare le impostazioni del modello di embedding nel nodo Embeddings Google Gemini.
- Confermare la selezione del modello di chat nel nodo Google Gemini Chat Model.
A questo punto, il workflow sarà completamente configurato e collegato agli account, alla cartella Drive e all'indice vettoriale.
Fase 6: Testare la Pipeline RAG
Per testare la pipeline RAG, aggiungere o aggiornare un documento nella cartella Google Drive per attivare il flusso di indicizzazione. Successivamente, porre una domanda tramite il punto di ingresso della chat e osservare come l'agente recupera il testo pertinente e genera una risposta. Ogni passaggio è visibile all'interno di n8n, consentendo un'ispezione e un debug agevoli.
Fase 7: Attivare il Workflow
Abilitare il workflow in n8n Cloud o eseguirlo nell'ambiente self-hosted. Il chatbot RAG sarà ora operativo, indicizzando automaticamente i nuovi documenti aziendali e rispondendo alle domande dei dipendenti con informazioni fondate e aggiornate.
Esempi di Pipeline RAG in n8n
Dopo aver compreso come una pipeline RAG si integra in n8n, è utile esaminare alcuni esempi concreti. I seguenti workflow illustrano diversi modi in cui i team implementano la RAG nella pratica, da configurazioni di base a soluzioni automatizzate più avanzate.
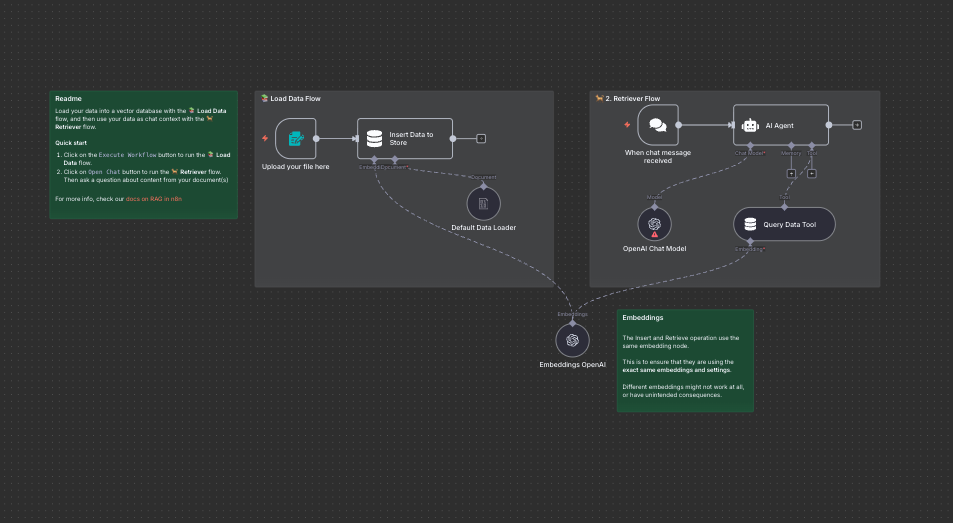
Template RAG di Avvio con Vector Store Semplici e Trigger da Modulo
Un workflow RAG pensato per i principianti, che dimostra come fornire a un agente informazioni provenienti da un PDF o un documento. Permette di caricare un file, generare embedding e interagire con il contenuto utilizzando un semplice database vettoriale:
Costruire Workflow Personalizzati Automaticamente con GPT-4o, RAG e Ricerca Web
Questo template illustra come trasformare una semplice richiesta in un workflow n8n automatizzato, integrando funzionalità RAG e di ricerca web. È lo strumento ideale per prototipare rapidamente automazioni complesse con una minima configurazione manuale:
Creare un Bot Esperto di Documentazione con RAG, Gemini e Supabase
Un workflow pratico che permette di costruire un chatbot RAG specializzato su un argomento specifico, indicizzando la documentazione e fungendo da "bibliotecario esperto" in grado di rispondere a domande con contesto fondato:

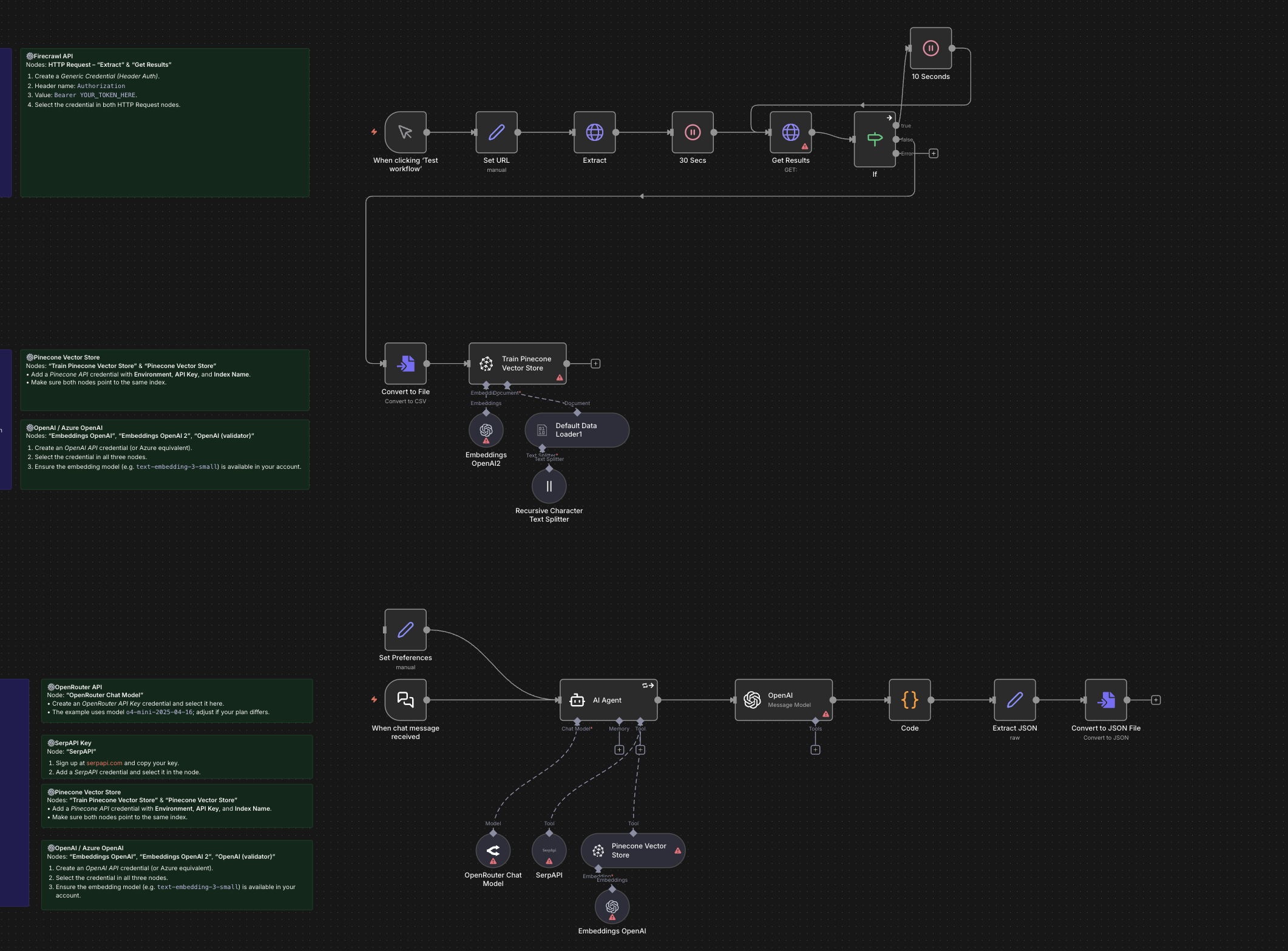
Chat RAG di Base
Un esempio più semplice di RAG che illustra una pipeline end-to-end utilizzando un database vettoriale in memoria per una prototipazione rapida. Dimostra l'ingestione dei dati, la creazione di embedding con un provider esterno, il recupero e la generazione della chat:
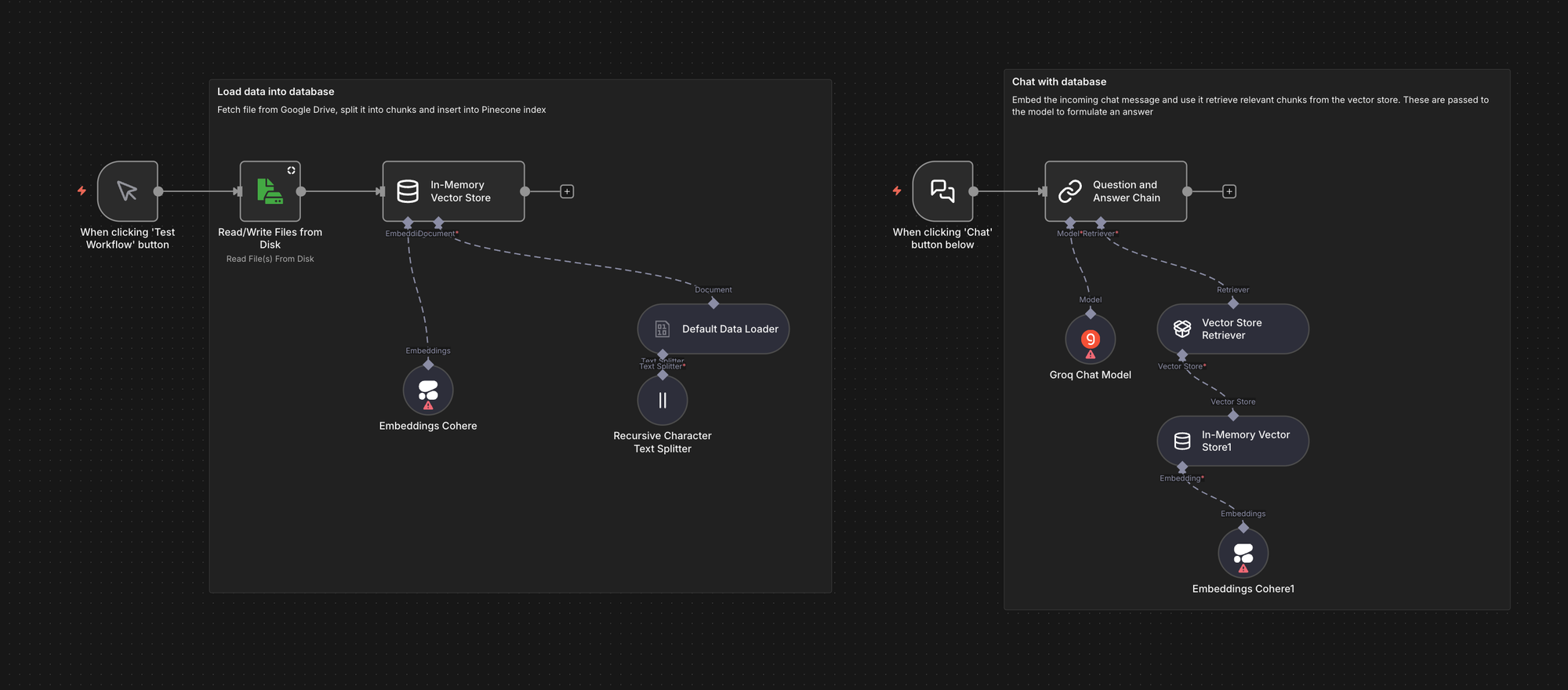
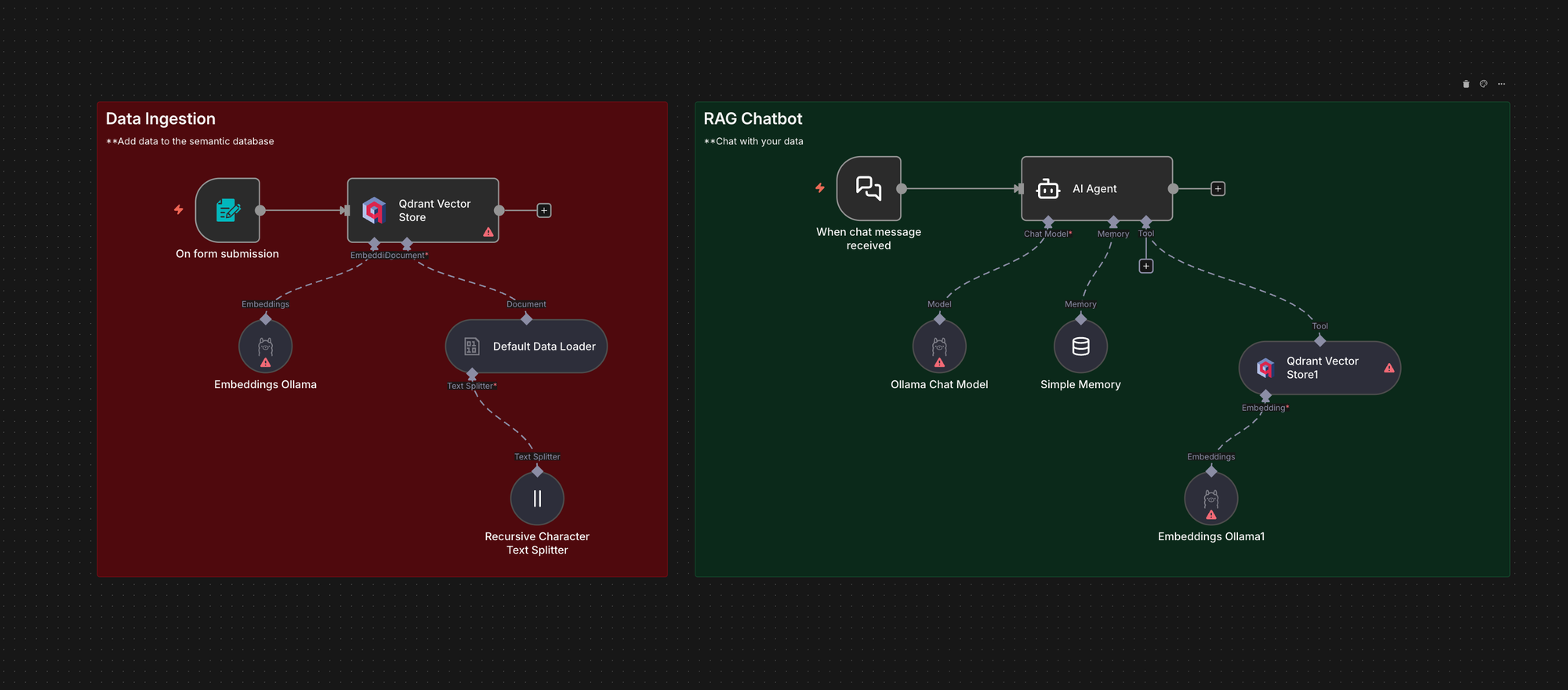
Chatbot Locale con Generazione Aumentata dal Recupero (RAG)
Questo workflow illustra come eseguire un chatbot RAG completamente locale utilizzando n8n con Ollama e Qdrant. Ingerisce file PDF in Qdrant, recupera i frammenti pertinenti al momento della query e risponde utilizzando un modello locale. Questa soluzione è particolarmente utile quando si desidera implementare la RAG senza inviare dati a API esterne:
Vantaggi e Sfide della RAG
La RAG offre vantaggi evidenti, dalla riduzione delle allucinazioni alla possibilità di riutilizzare la conoscenza tra i team, ma introduce anche nuove sfide legate alla qualità dei dati, alle prestazioni e alla sicurezza. Comprendere questi compromessi è fondamentale prima di procedere con la costruzione, e n8n offre un modo pratico per gestirli all'interno di un unico sistema.
Vantaggi
- La RAG riduce le allucinazioni ancorando le risposte a dati reali e verificati.
- Consente aggiornamenti semplici e rapidi senza la necessità di riaddestrare il modello.
- Rende la conoscenza riutilizzabile, permettendo a più team di accedere agli stessi documenti indicizzati.
- Accelera la sperimentazione, consentendo di modificare modelli o fonti di dati senza dover riscrivere codice.
È importante sottolineare come, nell'ambiente n8n, questi benefici siano amplificati dal fatto che l'intera pipeline risiede in un'unica interfaccia visiva.
Sfide
- L'efficacia della RAG è strettamente dipendente dalla qualità dei dati forniti.
- Le fasi di "chunking" (suddivisione in frammenti) e recupero potrebbero richiedere una calibrazione fine, soprattutto quando i documenti presentano strutture eterogenee o il testo recuperato non è sufficientemente specifico per la domanda.
- La pipeline può introdurre latenza, specialmente con documenti di grandi dimensioni o quando il database vettoriale impiega tempo a rispondere.
- È fondamentale considerare anche gli aspetti di sicurezza, poiché gli embedding e i frammenti archiviati potrebbero contenere informazioni interne sensibili che devono essere adeguatamente protette.
n8n offre un ambiente centralizzato per monitorare e bilanciare questi compromessi, facilitando gli aggiustamenti necessari.
Domande Frequenti sulle Pipeline RAG
Come si confronta una pipeline RAG in LangChain con la costruzione in n8n?
LangChain è una soluzione eccellente per chi desidera un controllo completo tramite codice, offrendo strumenti granulari per il "chunking", l'embedding, il recupero e l'orchestrazione. n8n, invece, replica lo stesso schema fondamentale attraverso un flusso visivo, riducendo al minimo la necessità di scrivere codice.
Posso ancora usare Python se costruisco la mia pipeline RAG in n8n?
Sì, è possibile continuare a utilizzare Python per le parti che lo richiedono realmente. n8n gestisce le operazioni di routine come l'ingestione, la creazione di embedding, la ricerca vettoriale e le chiamate ai modelli, riducendo la quantità di script di manutenzione da scrivere. Qualora fosse necessaria una trasformazione personalizzata o una funzione di scoring specifica, è possibile impiegare il nodo Code per eseguire un breve snippet Python e reindirizzare il risultato nel workflow.
Ho bisogno di codice per costruire una pipeline RAG?
Per costruire la pipeline RAG centrale, non è richiesto l'uso di codice. Le fasi di ingestione, suddivisione, creazione di embedding, archiviazione vettoriale, recupero, prompting e generazione possono essere tutte gestite visivamente in n8n. Il codice diventa quindi un'opzione, da aggiungere solo per logiche avanzate o specifiche della propria organizzazione.
Come si integra una pipeline RAG basata su Haystack con n8n?
Haystack è un framework robusto per il recupero, il ranking e la ricerca in Python. È possibile mantenere Haystack per logiche di recupero specifiche e lasciare che n8n gestisca l'orchestrazione circostante. n8n può avviare job Haystack, passare documenti o query alla pipeline, gestire i tentativi e connettere i risultati a sistemi a valle. Alcuni team scelgono di sostituire completamente Haystack con nodi visivi per semplificare la manutenzione.
Conclusioni
L'esistenza della RAG è motivata dall'incapacità dei modelli di fondazione di rispondere in modo affidabile a domande basate su dati interni specifici. In configurazioni ricche di codice, una pipeline RAG richiede numerosi servizi e script personalizzati. Con n8n, è possibile sfruttare template predefiniti e nodi visivi per costruire e implementare una pipeline RAG con pochissimo o nessun codice boilerplate. Questo approccio consente di mantenere il controllo, la chiarezza e la flessibilità senza essere sommersi dalle complessità di configurazione.
Cosa c'è Dopo?
Per chi desidera approfondire ulteriormente le pipeline RAG e le loro implementazioni con n8n, esistono risorse aggiuntive che vanno oltre le basi, offrendo walkthrough di pipeline complete, esempi di configurazioni reali e l'esplorazione di pattern di automazione avanzati.
- Si osserva una tendenza crescente verso i workflow RAG "agentici" — sistemi che non si limitano a recuperare e rispondere, ma sono anche in grado di verificare, raffinare e migliorare i propri risultati. Questa guida si concentra sulle fondamenta, ma una volta stabilite, il passo successivo è insegnare alla propria pipeline a valutare e rafforzare il proprio output.
- Costruire chatbot RAG personalizzati con n8n: Un articolo dettagliato che spiega come connettere qualsiasi fonte di conoscenza, indicizzarla in un database vettoriale e costruire un chatbot basato su AI utilizzando i workflow visivi di n8n.
- Indicizzare documenti da Google Drive a Pinecone con n8n: Un template di workflow pronto all'uso che monitora una cartella Drive e indicizza automaticamente i nuovi file in un database vettoriale Pinecone. Rappresenta un ottimo punto di partenza per sistemi RAG basati su documenti.
- Creare un Agente RAG in n8n per Principianti: Una guida passo-passo completa per i neofiti.
La pipeline RAG più efficace è quella che si adatta specificamente ai vostri dati e alle vostre esigenze. Queste risorse forniscono un set di strumenti per costruire, migliorare e scalare le vostre soluzioni. n8n rende tutto questo possibile, eliminando la complessità del codice boilerplate!